TripleO Split Control Plane from Compute/Storage Support¶
https://blueprints.launchpad.net/tripleo/+spec/split-controlplane
This spec introduces support for a mode of deployment where the controlplane nodes are deployed and then batches of compute/storage nodes can be added independently.
Problem Description¶
Currently tripleo deploys all services, for all roles (groups of nodes) in a single heat stack. This works quite well for small to medium size deployments but for very large environments, there is considerable benefit to dividing the batches of nodes, e.g when deploying many hundreds/thousands of compute nodes.
Scalability can be improved when deploying a fairly static controlplane then adding batches of e.g compute nodes when demand requires scale out. The overhead of updating all the nodes in every role for any scale out operation is non-trivial and although this is somewhat mitigated by the split from heat deployed servers to config download & ansible for configuration, making modular deployments easier is of benefit when needing to scale deployments to very large environments.
Risk reduction - there are often requests to avoid any update to controlplane nodes when adding capacity for e.g compute or storage, and modular deployments makes this easier as no modification is required to the controalplane nodes to e.g add compute nodes.
This spec is not intended to cover all the possible ways achieving modular deployments, but instead outline the requirements and give an overview of the interfaces we need to consider to enable this flexibility.
Proposed Change¶
Overview¶
To enable incremental changes, I’m assuming we could still deploy the controlplane nodes via the existing architecture, e.g Heat deploys the nodes/networks and we then use config download to configure those nodes via ansible.
To deploy compute nodes, we have several options:
Deploy multiple “compute only” heat stacks, which would generate ansible playbooks via config download, and consume some output data from the controlplane stack.
Deploy additional nodes via mistral, then configure them via ansible (today this still requires heat to generate the playbooks/inventory even if it’s a transient stack).
Deploy nodes via ansible, then configure them via ansible (again, with the config download mechanism we have available today we’d need heat to generate the configuration data).
The above doesn’t consider a “pure ansible” solution as we would have to first make ansible role equivalents for all the composable service templates available, and that effort is out of scope for this spec.
Scope and Phases¶
The three items listed in the overview cover an incremental approach and the first phase is to implement the first item. Though this item adds an additional dependency on Heat, this is done only to allow the desired functionality using what is available today. In future phases any additional dependency on Heat will need to be addressed and any changes done during the first phase should be minimal and focus on parameter exposure between Heat stacks. Implementation of the other items in the overview could span multiple OpenStack development cycles and additional details may need to be addressed in future specifications.
If a deployer is able to do the following simple scenario, then this specification is implemented as phase 1 of the larger feature:
Deploy a single undercloud with one control-plane network
Create a Heat stack called overcloud-controllers with 0 compute nodes
Create a Heat stack called overcloud-computes which may be used by the controllers
Use the APIs of the controllers to boot an instance on the computes deployed from the overcloud-computes Heat stack
In the above scenario the majority of the work involves exposing the correct parameters between Heat stacks so that a controller node is able to use a compute node as if it were an external service. This is analogous to how TripleO provides a template where properties of an external Ceph cluster may be used by TripleO to configure a service like Cinder which uses the external Ceph cluster.
The simple scenario above is possible without network isolation. In the more complex workload site vs control site scenario, described in the following section, network traffic will not be routed through the controller. How the networking aspect of that deployment scenario is managed will need to be addressed in a separate specification and the overall effort will likely to span multiple OpenStack development cycles.
For the phase of implementation covered in this specification, the compute nodes will be PXE booted by Ironic from the same provisioning network as the controller nodes during deployment. Instances booted on these compute nodes could connect to a provider network to which their compute nodes have direct access. Alternatively these compute nodes could be deployed with physical access to the network which hosts the overlay networks. The resulting overcloud should look the same as one in which the compute nodes were deployed as part of the overcloud Heat stack. Thus, the controller and compute nodes will run the same services they normally would regardless of if the deployment were split between two undercloud Heat stacks. The services on the controller and compute nodes could be composed to multiple servers but determining the limits of composition is out of scope for the first phase.
Example Usecase Scenario: Workload vs Control Sites¶
One application of this feature includes the ability to deploy separate workload and control sites. A control site provides management and OpenStack API services, e.g. the Nova API and Scheduler. A workload site provides resources needed only by the workload, e.g. Nova compute resources with local storage in availability zones which directly serve workload network traffic without routing back to the control site. Though there would be additional latency between the control site and workload site with respect to managing instances, there would be no reason that the workload itself could not perform adequately once running and each workload site would have a smaller footprint.
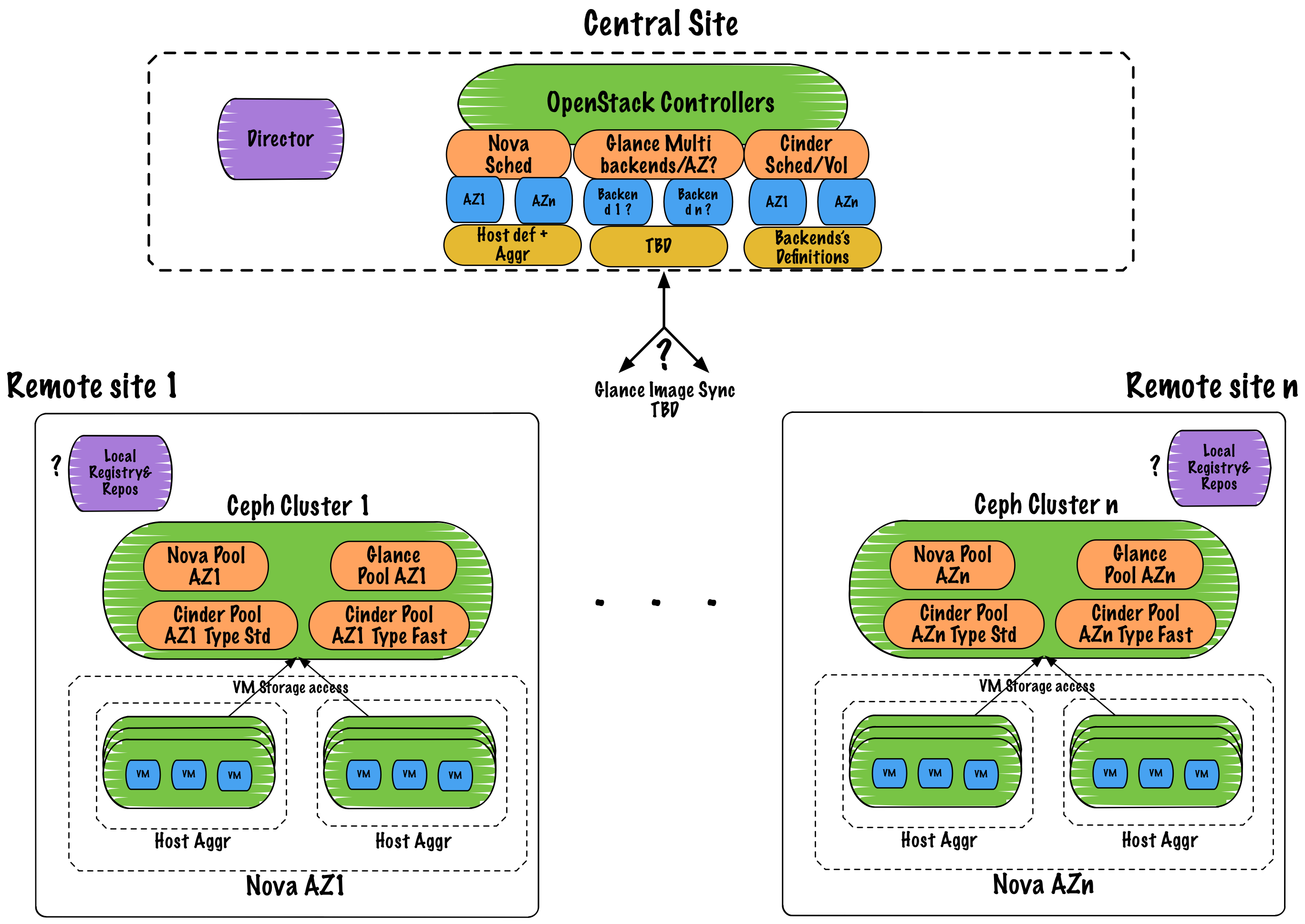
This scenario is included in this specification as an example application of the feature. This specification does not aim to address all of the details of operating separate control and workload sites but only to describe how the proposed feature, deployment of independent controlplane and compute nodes, for TripleO could be built upon to simplify deployment of such sites in future versions of TripleO. For example the blueprint to make it possible to deploy multiple Ceph clusters in the overcloud [1] could be applied to provide a separate Ceph cluster per workload site, but its scope only focuses on changes to roles in order to enable only that feature; it is orthogonal to this proposal.
Alternatives¶
Alternatives to the incremental change outlined in the overview include reimplementing service configuration in ansible, such that nodes can be configured via playbooks without dependency on the existing heat+ansible architecture. Work is ongoing in this area e.g the ansible roles to deploy services on k8s, but this spec is primarily concerned with finding an interim solution that enables our current architecture to scale to very large deployments.
Security Impact¶
Potentially sensitive data such as passwords will need to be shared between the controlplane stack and the compute-only deployments. Given the admin-only nature of the undercloud I think this is OK.
Other End User Impact¶
Users will have more flexibility and control with regard to how they choose to scale their deployments. An example of this includes separate control and workload sites as mentioned in the example use case scenario.
Performance Impact¶
Potentially better performance at scale, although the total time could be increased assuming each scale out is serialized.
Other Deployer Impact¶
None
Developer Impact¶
It is already possible to deploy multiple overcloud Heat stacks from one undercloud, but if there are parts of the TripleO tool-chain which assume a single Heat stack, they made need to be updated.
Implementation¶
Assignee(s)¶
- Primary assignee:
shardy
- Other assignees:
gfidente fultonj
Work Items¶
Proof of concept showing how to deploy independent controlplane and compute nodes using already landed patches [2] and by overriding the EndpointMap
If there are problems with overriding the EndpointMap, rework all-nodes-config to output the “all nodes” hieradata and vip details, such that they could span stacks
Determine what data are missing in each stack and propose patches to expose the missing data to each stack that needs it
Modify the proof of concept to support adding a separate and minimal ceph cluster (mon, mgr, osd) through a heat stack separate from the controller node’s heat stack.
Refine how the data is shared between each stack to improve the user experience
Update the documentation to include an example of the new deployment method
Retrospect and write a follow up specification covering details necessary for the next phase
Dependencies¶
None.
Testing¶
Ideally scale testing will be performed to validate the scalability aspects of this work. For the first phase, any changes done to enable the simple scenario described under Scope and Phases will be tested manually and the existing CI will ensure they do not break current functionality. Changes implemented in the follow up phases could have CI scenarios added.
Documentation Impact¶
The deployment documation will need to be updated to cover the configuration of split controlplane environments.
