NUMA-aware vSwitches¶
https://blueprints.launchpad.net/nova/+spec/numa-aware-vswitches
vSwitches such as Open vSwitch (with kernel or DPDK datapath), Lagopus, or Contrail DPDK vRouter all have some level of NUMA affinity. This can occur because they use one or more physical network interfaces, usually connected via PCIe, or they use userspace processes that are affined to a given NUMA node. This NUMA affinity is not currently taken into account when creating an instance. This can result in up to a 50% performance drop [1].
Problem description¶
In I/O (PCIe) based NUMA scheduling, nova tackled the problem of NUMA affinity for PCIe devices when using the libvirt driver. This was done by utilizing the NUMA information for these PCIe devices that was provided by libvirt. However, the use of software switching solutions complicates matters compared to switching that is done in hardware. In these cases, we do not pass through entire PCI devices or virtual functions but rather a VIF object. Nonetheless, the vSwitch will utilize physical hardware to access physical networks and will have an affinity to specific NUMA nodes based on this. This NUMA affinity is not currently accounted for, which can result in cross-NUMA node traffic and significant packet processing performance penalties.
Important
This spec focuses solely on traffic between instances and physical NICs or “physical to virtual (PV)” traffic. Traffic between instances, or “virtual to virtual (VV)” traffic, is not within the scope of this spec.
Worked Example: OVS-DPDK¶
For those interested in the nitty-gritty of how this works, let’s use an example using one possible vSwitch solution, OVS-DPDK. Consider the following network topology:
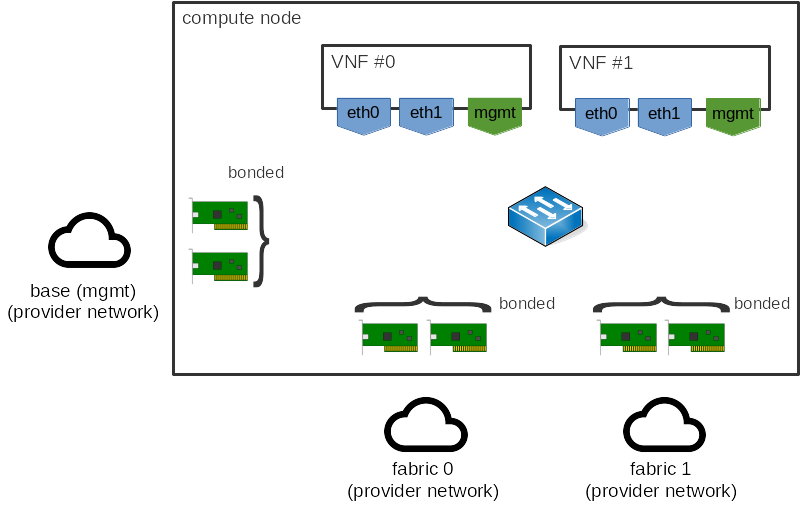
In the above, we have two guests, each with a number of interfaces, along with
a number of host interfaces. When using OVS-DPDK, the guest interfaces would
typically be dpdkvhostuser or dpdkvhostuserclient ports [2], while the
physical network interfaces in the host would be dpdk ports [3]. Each of
these ports has a number of transmit (Tx) and receive (Rx) queues to actually
move packets to and from each interface.
OVS-DPDK uses a number of Poll Mode Driver processes (PMDs) [4] to do the
actual packet processing and each queue is assigned to a PMD. If DPDK was
compiled with libnumactl and CONFIG_RTE_LIBRTE_VHOST_NUMA=y [5], this
assignment is NUMA aware and a queue will be assigned to the same NUMA node as
either:
The physical network interface the queue is from, for a
dpdkinterfaceOne of the NUMA nodes associated with the guest, for a
dpdkvhostuserordpdkvhostuserclientinterface
If multiple queues exist (i.e. multi-queue), assigning is done per queue, ensuring that an individual PMD does not become a bottleneck. Where multiple PMDs exist for a given NUMA node, as is often the case, assigning is done in a round-robin fashion. If there is no local (in the sense of NUMA locality) PMD to service the queue, the queue will be assigned to a remote PMD.
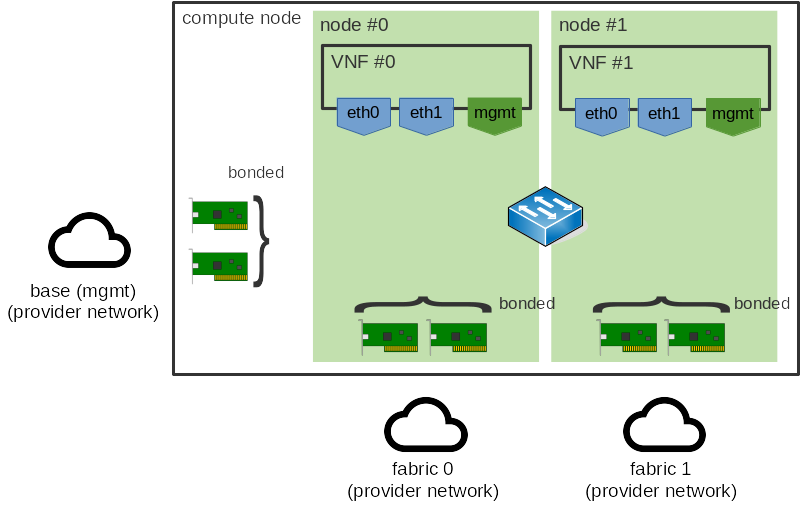
So, let’s further build upon the above example and add this NUMA affinity into the mix. We will say there are two NUMA nodes and both the guests and the NICs are split between these nodes. This gives us something like so:
What we want to avoid is cross-NUMA node traffic. We’re not particularly concerned with VM <-> VM traffic (more on this in a bit), so such traffic would probably look something like this:
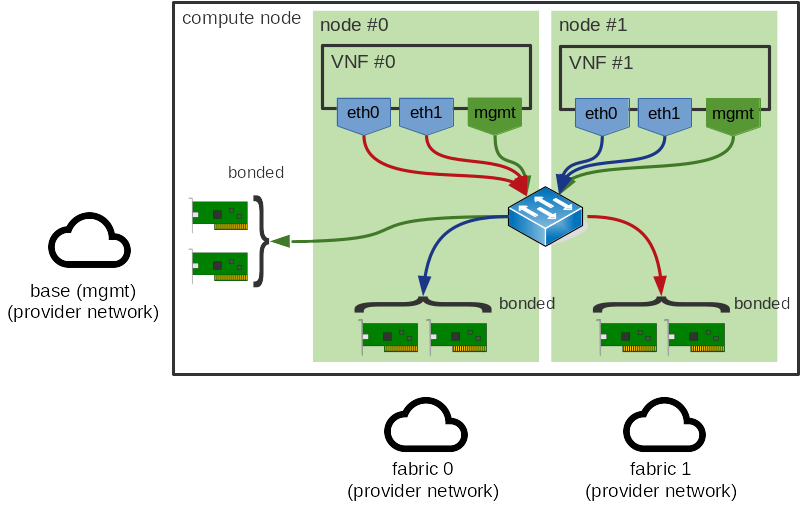
Note
In OVS-DPDK, egress traffic (VM -> Phy) is not particularly costly as the PMD dequeuing packets from the guest queue will be located on the same NUMA node as the guest queue itself. Meanwhile, the enqueue onto the physical network interface’s queue is efficient thanks to DMA. However, the return path is much more costly as the enqueue to the guests queue cannot benefit from DMA.
This is the root cause of the issue: clearly the guest should have been put on the same NUMA node as the NIC it’s using, as seen below. This is what we wish to resolve with this spec.
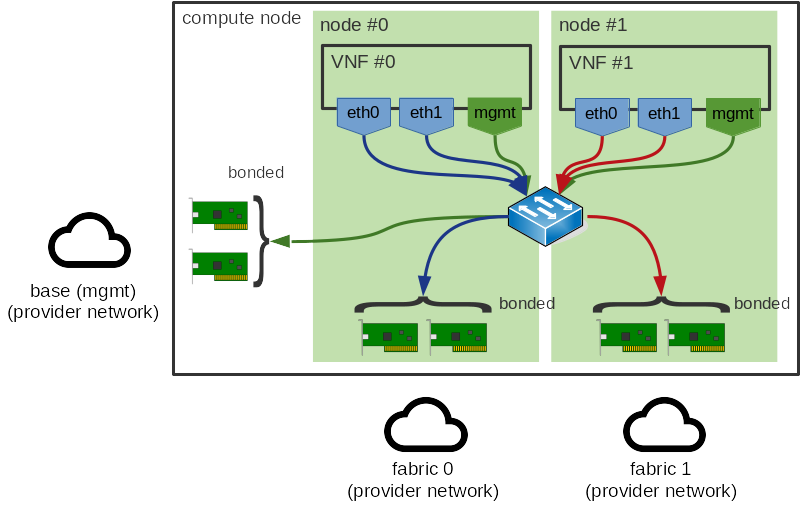
Use Cases¶
As a user, I want to ensure I’m getting the maximum benefit from my highly tuned, high-performance vSwitch solution
As an operator, I don’t want to revert to custom hacks like dynamically adjusting vcpu_pin_set just so I can deliver the performance my customers demand.
Proposed change¶
As we want to provide a generic solution that works for multiple network backends, the solution should be built upon neutron and its concepts. neutron does not expose things like Open vSwitch’s bridges, but rather provides network objects like networks, subnets, and ports. Ports aren’t particularly helpful to us as we’re not attaching a given port directly to the guest. Instead, we will utilize networks or, more specifically, networks that utilize physical NICs. There are two types of network technology in play: flat and VLAN, a.k.a. L2 physical or non-tunneled networks, and GRE or VXLAN, a.k.a. L3 tunneled networks.
Note
Others mechanisms, such as OPLEX (Cisco proprietary), are supported in addition to VLAN, VXLAN et al. through the use of non-default Neutron backends. These are considered out-of-scope for this spec. We also consider local, which does not provide external network connectivity, out-of-scope.
Note
The network technologies discussed here are distinct from the network types neutron offers, such as provider networks [6] [7] and tenant networks [8] [9], and are different again from the architectures available, such as pre-created networking or self-serviced networking. The network types and architectures focus more on who can configure a given network (users for tenant networks, admin for both) and where that configuration is found (for provider networks, generally configuration files, but an admin can explicitly override this). The table below illustrates this.
Common name |
User-configurable? |
L2 (non-tunneled) |
L3 (tunneled) |
|---|---|---|---|
Provider network |
No |
Yes |
No |
Tenant network |
Yes |
Yes (not common) |
Yes (common) |
This entire spec focuses on the technologies as these are what determine how traffic will egress from a compute node, which is the primary concern here.
- Physical networks
Physical networks, or physnets, are identified through the use of an arbitrary label. In the case of the Open vSwitch (OVS) ML2 driver, these labels are mapped to a given OVS bridge containing the physical interfaces using the
[ovs] bridge_mappingsneutron configuration option. For example:openvswitch_agent.ini¶[ovs] bridge_mappings = provider:br-provider
This will map the physnet
providerto an OVS bridgebr-provider. It is expected that this bridge will contain a logical interface (you can use bonded NICs to provide failover). A similar configuration option exists for the Linux Bridge ML2 driver:[linux_bridge] physical_interface_mappings.- Tunneled networks
Networks with a tunnel overlay, or tunneled networks, may also provide external network connectivity. There can be many tunneled networks but only one logical interface (you can use bonded NICs to provide failover) on a host should be handling traffic for these networks. This interface is configured using the
[ovs] local_ipneutron configuration option. For example:openvswitch_agent.ini¶[ovs] local_ip = OVERLAY_INTERFACE_IP_ADDRESS
This will result in all VXLAN or GRE traffic using the interface whose IP corresponds to
OVERLAY_INTERFACE_IP_ADDRESS. A similar configuration option exists for the Linux Bridge ML2 driver for VXLAN traffic:[vxlan] local_ip. This driver does not support GRE traffic.
It is possible for both physical and tunneled networks to be used on the same host. Given all of this, we propose the following changes.
Changes¶
Configuration options¶
We propose adding a new configuration option and multiple dynamically-generated configuration groups.
The
[neutron] physnetsconfiguration option will list all physnets for which you wish to provide NUMA affinity.The
[neutron_tunnel]configuration group will allow configuration of the tunneled networks. Only one configuration group is required for these since all tunneled networks must share a logical interface. This group will contain a single configuration option,numa_nodes, which lists the host NUMA node(s) to which tunneled networks are affined.Multiple
[neutron_physnet_$PHYSNET]configuration groups, one per each$PHYSNETin[neutron] physnets, will allow configuration of these physnets. Each of these configuration groups will contain a single configuration option each,numa_nodes, which lists the host NUMA node(s) to which networks using this physnet are affined.
The groups will all be generated dynamically, which is required as the values
of $PHYSNET in [neutron_physnet_$PHYSNET] are arbitrary and can only be
identified from the corresponding values in [neutron] physnets.
This will result in configuration files like the below:
[neutron]
physnets = physnet0,physnet1
[neutron_physnet_physnet0]
numa_nodes = 0
[neutron_physnet_physnet1]
numa_nodes = 0,1
[neutron_tunnel]
numa_nodes = 1
where:
[neutron] physnetsA list of strings corresponding to the names of all neutron provider network physnets configured on this host.
Note
Using a combination of neutron’s hierarchical port binding and multiprovider network features, it is possible for neutron to dynamically generate a network segments with a given physnet. This is considered out of scope for this feature.
[neutron_physnet_$PHYSNET]A section of opts corresponding to one of the physnets defined in
[neutron] physnets. This in turn has the following keys:numa_nodesA list of integers of NUMA nodes associated with this backend. It is defined as a list to cater for cross NUMA bonds and multipath routing. If this is empty, the physnet has no NUMA affinity assigned to it.
Note
A smart enough vSwitch with a active-active cross-NUMA node bond could use the NUMA affinity of the VM interface as an input to the hash for selecting the bond peer has to ensure no cross-NUMA traffic for inter-host traffic. Alternatively, a dumb one could have os-vif hardcode it using a OpenFlow multipath action and some other Open vSwitch fanciness to set the MAC affinity to NUMA local bond peer. This is outside of the scope of this spec.
[neutron_tunnel]The same as
[neutron_physnet_$PHYSNET]but for the interface used by tunnel networks.
As noted previously, a host may use physnets networks, tunneled networks or a combination of both. As a result, not all configuration values may be specified on a given host.
This configuration will be generated by an orchestration tool at deployment time in the same way that general host network configuration is generated. This is because identifying the NUMA affinity for an arbitrary network is a difficult problem that grows in complexity with the design of the networks and VNFs. The orchestration tool is responsible for configuring how physical NICs are used by the various neutron networks and with only a little extra work can extend this to include NUMA affinity (for example, by combining information from tools like ethtool with information from sysfs).
NUMA affinity will be provided for all networks with a physnet and a defined
[neutron_physnet_$PHYSNET] group and for all tunneled networks, assuming
[neutron_tunnel] is defined. This will be stored as part of a host’s
NUMACell object. If a given network is not defined in any such option, no
NUMA affinity will be provided. As with other devices that provide NUMA
affinity, namely PCI or SR-IOV [10] devices, attempting to boot an instance
may fail in a number of cases. These are described later.
Network API Client¶
The network API client in nova currently provides a method,
create_pci_requests_for_sriov_ports [11], which retrieves information
about physnets and VNIC types of each port requested when booting an instance
for the purpose of creating PCI requests for SRIOV ports. This will be made
more generic and extended to get information about the tunneled status of any
requested networks. This information will be stored (but not persisted) in a
new object, InstanceNUMANetworks, for later consumption.
Note
As with the existing SR-IOV feature, this will only handle the case where an entire network, as opposed to a segment of the network, is associated with the physnet.
Scheduling¶
In addition to the configuration change, we will need to start including the
list of requested phynets and tunneled networks, stored in the new
InstanceNUMANetworks object, as a field of the RequestSpec object. This
field will not be persisted in the database. We require this information so we
can use it to build the NUMA topology of the instance on the host as part of
scheduling but it does not need to be stored after this. We also need to extend
the limits dictionary returned by the NUMATopologyFilter to include
information about the networks. This is necessary so we have something to
reference during the claim stage on the compute. In both cases, the cached
information will need to be updated in the event of a move operation.
Virtualization driver¶
Only the libvirt driver currently supports the full breadth of NUMA affinity
features required for this feature. While other drivers, notably Hyper-V, do
support some NUMA features, these are related to guest NUMA topologies and not
placement of vCPU processes across host NUMA nodes. The NUMA fitting code,
found in numa_fit_instance_to_host, will be updated to consume a new
InstanceNUMANetworks object and use this to determine which host NUMA nodes
to use. The InstanceNUMANetworks object will be built from information in
the RequestSpec objects or scheduler limits and passed in by the caller of
this function.
Potential issues¶
As noted above, this is a rather difficult issue to solve sanely and, as a result, there are a number of situations that need special workarounds. The first arises where physical NICs from different NUMA nodes are bonded. This will not break the world but is not intended to have anything but poor performance. This exact situation can arise in SR-IOV too and generally occurs because:
The operator has misconfigured something
The operator does not care about optimal performance
The operator wants to provide resiliency by spreading work across NICs and cannot or will not use two NICs from the same NUMA node
Given that we can’t determine if this was intentional or not, we have defined
numa_nodes as a list rather than a single integer. This will allow us to
capture the combined NUMA affinity of the bonded NICs.
The second situation is guests with complex, multi-NIC configurations. Most VNFs utilize multiple interfaces, some of which will be used for VM management interfaces (SSH, logging, SNMP, …) while the remainder will be used for actual data plane interfaces. NUMA affinity doesn’t matter for the former so we can ignore these, however, if the latter ports have different affinities, it can be impossible to determine a natural NUMA affinity. This can be seen below:
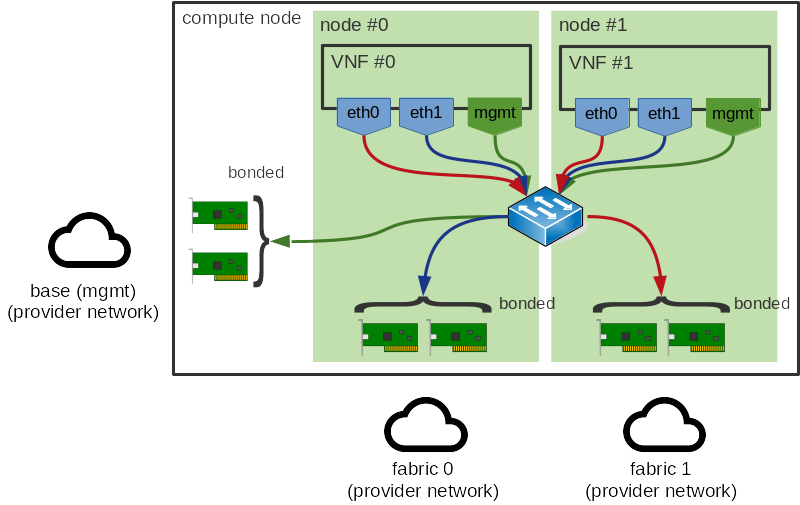
This exact situation occurs with PCI and SR-IOV devices and here, as with those devices, we expect users to define a multi-node guest topology or to avoid specifying NUMA affinity for the non-data plane interfaces.
The third situation is VM to VM traffic. Current NFV deployments do not generally care about VM to VM traffic as it’s highly unlikely that two related VNFs would ever be intentionally collocated on a given host. As such, VM to VM traffic is considered out of scope for this spec.
The fourth and final situation is interfaces that are attached after creating the instance. Interfaces for which NUMA affinity is required must be requested when creating instances and any interfaces attached after this will not have NUMA affinity applied to them. This is required to limit the scope of this feature and will be resolved in a future spec, however, a resize operation or similar can be used after attaching new interfaces to gain NUMA affinity for these interfaces.
Alternatives¶
There are multiple possible solutions to this issue of various levels of complexity.
We could store the static backend-NUMA mapping in neutron instead and pass this over the wire as part of the VIF request. As neutron is responsible for all things network’y, storing this information in nova might appear to break the separation of concerns between the two services. However, this is only partially true. While neutron is responsible for creating network elements such as ports and bridges, it is nova that is responsible for wiring them up to instances. This does not get nova into the business of actually creating the underlying network elements, but rather it will now store additional metadata about said elements. Moving this configuration into neutron would complicate matters for little to no gain.
An even more elaborate alternative would be dynamically generate this information in neutron, rather than hardcoding it in either nova or neutron. This information could be exposed via a new extension or similar. This would appear to incur the least amount of effort on a deployer’s side and would seem like the most intelligent thing to do. However, this is not perfect either. Implementing this functionality would require changes to nearly every backend in neutron and may not even be possible for some backends and some particularly complex configurations. As noted previously, we have access to information on the overall network design at deployment time and discarding that in favour of dynamic generation introduces unnecessary magic to the formula.
We could go all in on placement from a neutron side and start storing information about the various backends from neutron. Nova would then be able to use this information in order to make its scheduling decisions. This is technically the best solution as it solves both this issue and a number of other issues, such as bandwidth-aware scheduling and discovery of the types of networks available on a compute node _before_ landing on that node. However, we don’t currently have a clear story for modelling NUMA resources in placement [12]. Given the tenant dataplane performance issues being faced right now, this seems untenable. However, that’s not to say we can’t migrate some of this information to placement in the future. This was discussed during the Rocky PTG in Dublin [13].
OpenDaylight (ODL) uses per host configuration stored in OVS (like bridge mappings), which are then read by ODL and populated into Neutron DB as pseudo agents. We could store the NUMA:physnet affinity per network on a per-host basis in OVS, eventually propagating this info to the VIF request for nova. However, this isn’t feasible for tenant networks as the NUMA topology of the host is not visible to a tenant. In addition, this relies on specific features of the network backend which might not be available in other backends.
Finally, and this is the nuclear option, we could simply embrace the fact that scheduling decisions in the NFV space are tough to do automatically and it might be better to delegate this to another system. To this end, we could simply expose a “deploy on this host NUMA node” knob and let users at it. This would simplify our lives and satisfy the requests of these users, but it is distinctly uncloudy and unlikely to gain any traction.
Data model impact¶
A new object, NUMANetworkInfo, will be added to store information about
networks associated with a host NUMA node. This will be mapped to a parent
NUMACell object using a network_info field and will be used to compare
against the requested networks for one or more instances during scheduling and
claiming.
A new object, InstanceNUMANetworks, will be added to store information
about whether the networks requested for or attached to an instance were
physnets or tunneled networks. They will be populated by a more generic
version of the create_pci_requests_for_sriov_ports function. They will not
be persisted and is merely stored as a way to get this information from the API
to the scheduler for use in filtering.
REST API impact¶
None.
Security impact¶
None.
Notifications impact¶
None.
Other end user impact¶
None.
Performance Impact¶
There will be a negligible increase in the time taken to schedule an instance on account of the additional NUMA affinity checks. However, network performance of some vSwitch solutions (OVS-DPDK, for example) will increase by up to 100%.
Other deployer impact¶
Deployment tooling will need to be enhanced to configure the new configuration option at deployment time.
Developer impact¶
This change will require changes to the scheduler but only the libvirt driver will provide the information necessary to properly schedule these requests. Additional drivers do not currently provide sufficient awareness of host NUMA information for this change to be incorporated in a meaningful manner. If this changes in the future, the drivers will need to be extended to consume the configuration option and request spec attributes.
Upgrade impact¶
The new configuration options will need to be created for each nova-compute
services nova.conf file. In addition, any database migrations will need to
be run.
Implementation¶
Assignee(s)¶
- Primary assignee:
stephenfinucane
- Other contributors:
sean-k-mooney
Work Items¶
Add support for the new configuration option and dynamic configuration groups.
Create a
NUMANetworkInfoobject. This will be used to store the NUMA-network configuration provided innova.conf, namely, if any physnets or tunneled networks are affinitized to this cell.Add a
network_infofield to theNUMACellobject, which will include network information about the host node in the form of aNUMANetworkInfoobject. This is required so nova-scheduler and nova-conductor can access this information during scheduling and claiming, respectively.Create a
InstanceNUMANetworksobject. This will be used to store the combined physnets or tunneled attributes of the networks requested for the instance.Make
create_pci_requests_for_sriov_portsmore generic. This can be used to fetch most of the information we need to populate the newInstanceNUMANetworksobject.Add a
numa_networksfield to theRequestSpecobject, which will be theInstanceNUMANetworksobject generated from the call tocreate_pci_requests_for_sriov_portsby the API service. This information will be used by theNUMATopologyFilterto filter out hosts that could not satisfy the request. This field will not be persisted as it is only needed by the scheduler when scheduling new instances.Modify the
numa_fit_instance_to_hostfunction to accept a newnuma_networksargument, which will be an instance ofInstanceNUMANetworks, and consider these when building NUMA topologies.Modify the
NUMATopologyFilterto populate anuma_networksfield for thelimitsdictionary. This will be populated with an instance ofInstanceNUMANetworksbuilt using the value ofRequestSpec.numa_networks. Pass theInstanceNUMANetworksobject tonuma_fit_instance_to_host.Modify the serialized models stored in
Instance.info_cache.network_infoto include something akin to thephysnetandtunneledfields for each network. This is required for claims during any move operation.Modify nova-conductor to build a
InstanceNUMANetworksobject from theInstance.info_cache.network_infofield, which can be used to populate theRequestSpecobject for any move operation.Modify how claims are done on the compute to account for network info from the
limits(passed down from the scheduler) when building the instance’s NUMA topology.
Dependencies¶
None. numa-aware-live-migration is required to support live migration of instances with any CPU pinning and NUMA topology functionality enable. However, given that live migration is currently broken for all NUMA use cases, the lack of live migration support for this particular NUMA’y use case should not be considered a blocker.
Testing¶
Like anything else that utilizes real hardware, this cannot be tested in the upstream CI. Instead, we will need to rely on unit tests, functional tests (with hardware mocked out), and downstream or third-party CIs to provide testing.
Documentation Impact¶
The feature will need to be documented in full, though we do get the
configuration documentation for free (thanks oslo_config.sphinxext).
References¶
History¶
Release Name |
Description |
|---|---|
Rocky |
Introduced |
