Support CNF Heal in v2 LCM API¶
https://blueprints.launchpad.net/tacker/+spec/support-nfv-solv3-heal-vnf
This specification enhances version 2 (v2) of Heal API for supporting CNF.
Problem description¶
Yoga release supported VNF Lifecycle Management (LCM) operations defined in ETSI NFV SOL002 v3.3.1 [1] and SOL003 v3.3.1 [2]. It also supported CNF Lifecycle Management with v2 APIs such as Instantiate API, Terminate API, and ChangeCurrentVnfPackage API.
However, v2 Heal API has not supported CNF yet. Supporting CNF in v2 LCM API makes Tacker more powerful generic VNFM.
Proposed change¶
This specification enhances the following API to support CNF.
Heal VNF (POST /v2/vnf_instances/{vnfInstanceId}/heal)
Definition of CNF healing¶
The definition of v2 CNF healing is the same as the v1 CNF healing.
For “Heal VNF instance with SOL003”, the heal operation is defined to be the termination and instantiation of the VNF.
For “Heal VNFC with SOL002”, Pod is mapped to VNFC. Pod can be a singleton or can be created using a workload resource in Kubernetes such as ReplicaSet, Deployment, DaemonSet, or StatefulSet. In the case of the singleton Pods, new Pods need to be created after deletion. On the other hand, in the case of workload resources, new Pods are automatically created by Kubernetes.
v2 Heal operation supports the following kinds defined in Kubernetes. They are same as v1 Heal operation.
Pod
ReplicaSet
Deployment
DaemonSet
StatefulSet
Note
Tacker supports the heal operation for singleton Pod or Pod that created using above workload resources. Pod created using Job and CronJob is out of scope because no heal operation is required.
When Users execute “Heal VNF instance with SOL003”, all Kubernetes resources
described in VNF Package are re-created, but, for the case of StatefulSet,
assigned PersistentVolume by the PersistentVolumeClaim which is automatically
created by Kubernetes is not deleted. Also, in “Heal VNFC with SOL002”,
only the Pods specified with the vnfcInstanceId,
which is mapped to VnfInstance.instantiatedVnfInfo.VnfcInfo.id
are re-created but other related resources are not deleted.
Note
Pod name that is stored in
VnfInstance.instantiatedVnfInfo.VnfcResourceInfo.computeResource.resourceId
may be different from the actual Pod name which acts in Kubernetes cluster
because Pod name may change when Kubernetes auto-healing or auto-scaling works.
DB needs to be synchronized before scaling and healing.
Information about DB Synchronization are described in
Error handling for unmatched resource id between Tacker and Kubernetes.
Options of Heal operation¶
The client can specify the target resources for healing with vnfcInstanceId in the API request. vnfcInstanceId is a list which indicates VNFC instances for which a healing action is requested.
Also, v2 Heal API supports all option specifying heal target resources such as network resources and storage resources in addition to compute resources. However, this option is not valid in the case of CNF heal because Kubernetes cannot control individual network and storage.
With the vnfcInstanceId, Tacker supports the following two patterns of healing.
- Pattern A. vnfcInstanceId is included in the request.
It specifies “Heal VNF instance with SOL002”. Only specified VNFC instances are healed.
- Pattern B. vnfcInstanceId is not included in the request.
It specifies “Heal VNF instance with SOL003”. All VNFC instances included in the VNF instance are healed.
Flow of Heal operation¶
There is no change from the current implementation except for InfraDriver (KubernetesDriver) processing.
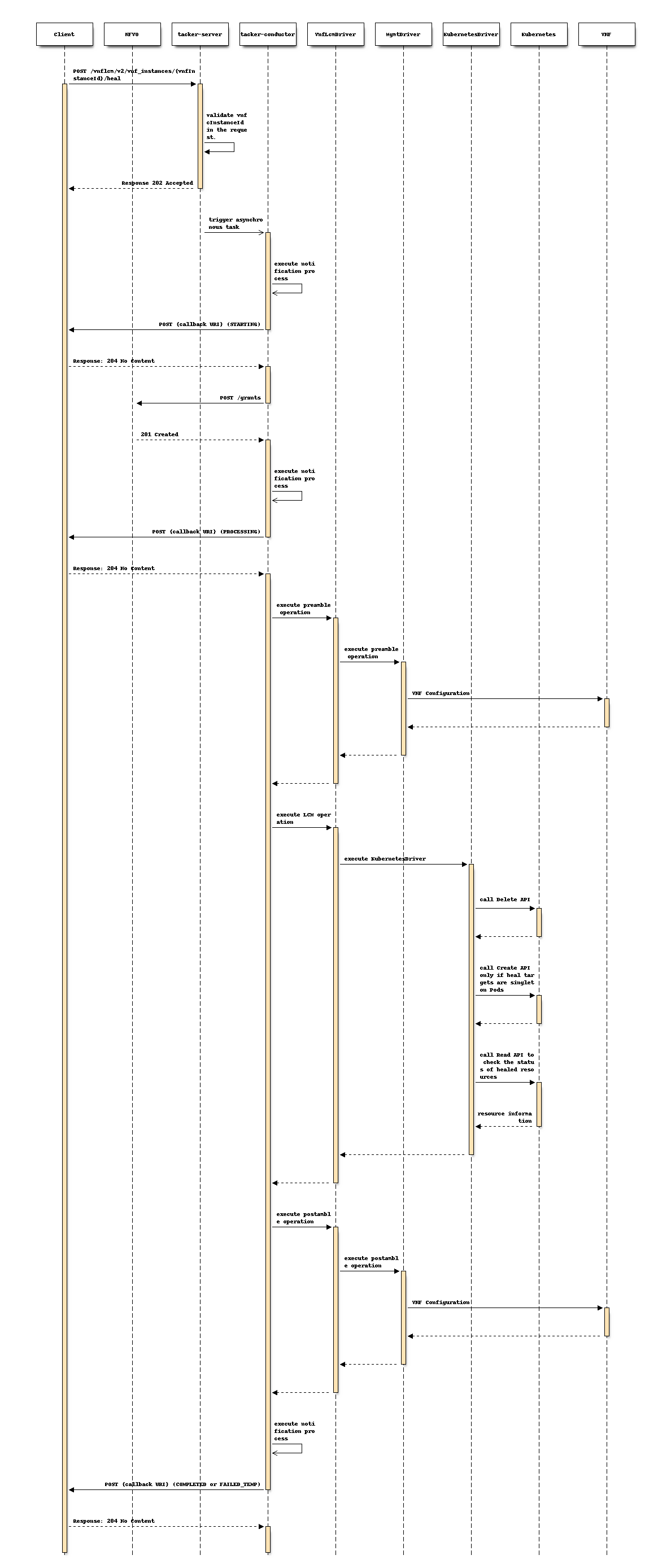
The procedure consists of the following steps as illustrated in above sequence:
Precondition: VNF instance in “INSTANTIATED” state.
Client sends a POST request for the Heal VNF Instance.
When the request contains
vnfcInstanceId, VNFM checks the existence of corresponding resources on the basis ofVnfInstance.instantiatedVnfInfo.VnfcResourceInfoin Tacker-database.VNFM sends endpoints such as Client a VNF lifecycle management operation occurrence notification with the “STARTING” state to indicate the start occurrence of the lifecycle management operation.
VNFM and NFVO exchange granting information.
VNFM sends endpoints such as Client a VNF lifecycle management operation occurrence notification with the “PROCESSING” state to indicate the processing occurrence of the lifecycle management operation.
MgmtDriver executes preamble operation according to a MgmtDriver script.
KubernetesDriver sends Kubernetes a Delete Pod request. In the case of pattern A, the requests are only for Pods corresponding to target VNFC. In the case of pattern B, the requests are for all Pods in the VNF.
KubernetesDriver sends Kubernetes a Create Pod request if heal targets are singleton Pods.
KubernetesDriver sends Kubernetes a Read resource request to check the status of healed resources.
MgmtDriver executes postamble operation according to a MgmtDriver script.
VNFM sends endpoints such as Client a VNF lifecycle management operation occurrence notification with the “COMPLETED” state or “FAILED_TEMP” state to indicate the result of the lifecycle management operation.
Postcondition: VNF instance in “INSTANTIATED” state, and healed.
Note
No explicit creation process is required for Pods created by workload resources in Kubernetes such as ReplicaSet, Deployment, DaemonSet, or StatefulSet, because Kubernetes automatically regenerates the Pods.
Kubernetes API support¶
KubernetesDriver calls following API to heal Pods and check status of them.
API Group |
Type |
API method |
|---|---|---|
apps (AppsV1Api) |
Read |
read_namespaced_replica_set_scale |
read_namespaced_deployment_scale |
||
read_namespaced_daemon_set |
||
read_namespaced_stateful_set_scale |
||
Delete |
delete_namespaced_pod |
|
Create |
create_namespaced_pod |
The arguments of Read API are name and namespace.
The arguments of Delete API are name, namespace, and body.
In the case of heal operation, the body is not set.
The arguments of Create API are name, namespace, and body.
The body includes resource definitions set from Kubernetes manifest files.
Error handling for unmatched resource id between Tacker and Kubernetes¶
Pods may be healed using Kubernetes’s own auto-healing functionality
without Tacker’s involvement.
This heal operation changes the name of Kubernetes resources.
Therefore, target VNFC may not be found by previous resource name
stored as VnfInstance.instantiatedVnfInfo.vnfcResourceInfo.computeResource.resourceId.
In this case, Tacker returns an error, and moves the operation status to FAILED_TEMP.
Note
The name of Kubernetes resources is changed by auto-healing only when using ReplicaSet, Deployment, DaemonSet and not when using StatefulSet.
To recover this error, the following three steps are required.
Call fail API to mark VnfLcmOpOcc as “FAILED”
Synchronize Databases of Tacker and Kubernetes
Call heal API with updated vnfcInstanceId
Note
This SPEC does not mention the method of synchronization. Tacker will support such synchronization functionality in future releases.
Note
After synchronization, vnfcInstanceId,
(which is mapped to VnfInstance.instantiatedVnfInfo.vnfcInfo.id)
of target VNFC is changed because VnfInstance.instantiatedVnfInfo.vnfcInfo.id
is based on resource name of Kubernetes in the current implementation.
Data model impact¶
None
REST API impact¶
None
Security impact¶
None
Notifications impact¶
None
Other end user impact¶
None
Performance Impact¶
None
Other deployer impact¶
None
Developer impact¶
None
Implementation¶
Assignee(s)¶
Hirofumi Noguchi <hirofumi.noguchi.rs@hco.ntt.co.jp>
Work Items¶
Implement InfraDriver process running on Tacker-conductor.
Add new unit and functional tests.
Update the Tacker user guide.
Dependencies¶
Heal operation
Depends on spec “Enhance NFV SOL_v3 LCM operation” [3].
Testing¶
Unit and functional test cases will be added for v2 CNF heal operations using Kubernetes VIM.
Documentation Impact¶
Description about v2 CNF heal operations will be added to the Tacker user guide.
