Fuel Library Modularization¶
https://blueprints.launchpad.net/fuel/+spec/fuel-library-modularization
This blueprint is about how we are going to split deployment workflow into pieces.
Problem description¶
Currently we have a gigantic monolithic deployment workflow, that takes almost an hour to complete. This does not allow us to develop quickly because testing takes far to much time. This also does not allow us to do more granular integration and functional testing.
Proposed change¶
In order to increase engineering velocity and ability for 3rd party users and developers to inject pieces into the deployment workflow we are going to change the architecture of the Fuel Library and make it more modular. The idea behind the modular architecture is the separation of our legacy monolithic manifest into a group of small manifests. Each of them will be designed to do only a limited part of the deployment. These manifests can be applied by Puppet in the same way as the monolithic manifest was applied before by the engine developed as a part of https://blueprints.launchpad.net/fuel/+spec/granular-deployment-based-on-tasks blueprint. The deployment process will be the sequential application of small manifests in the defined order.
Moving from a large manifests to small pieces has several important advantages:
- Independent development. Each developer can work only with those Fuel components he is currently interested in. The separate manifest can be dedicated wholly to a single task without interfering with components and developers. Every ask may require the system to be in a defined state before the deployment can be started and the task may require some input data be available. Other than these each task is on it’s own.
- Granular testing. Previously testing have been far too time consuming because any change required the whole deployment to be started from the scratch and there was no way to test only a part of the deployment which is related to the changes made. With granular deployment any finished task can be tested independently. Testing can be even automated with autotests and with environment snapshotting and reverting as well and being run manually by the developer on his test sysem.
- Encapsulation. Puppet is known to be to very good at code reuse. Usually you cannot just take any third party module or manifests and hope that it will work as designed within your Puppet infrastructure without neither modifications nor unexpectedly breaking something. These problems mostly come from the basic design of Puppet, the way it deems all resources unique within the catalog and the way it works with dependencies and ordering. There are techniques and methods to overcome these limitation, but they are not absolutely effective, and usually problems still persist. Using modular manifests bypasses these problems, because every single task will use its own catalog and will not directly mess with other tasks.
- Self-Testing. Granular architecture allows us to make test for every deployment task. These tests can be run either after the task to check if it have successfuly finished or before the task to check if the system is in the required state. Pre and post tests can be used either by the developer as acceptance tests or by the CI system to determine if the changes can be merged or during the real deployment to control the deployment process and to raise an alarm if something went wrong.
- Using multiple tools. Sometimes there can be a task that is very hard to be done using Puppet and some other methods or tools would be able to do it much easier or better. Granular deployment allows us to use any tools we see fit for the task, from shell scripts to Python or Ruby or even binary executables. Tasks, tests and pre/post hooks can be implemented using anything the developer knows best. For the first release only pre/post hooks can use non-Puppet tasks.
Alternatives¶
None
Data model impact¶
None
REST API impact¶
None
Upgrade impact¶
None
Security impact¶
None
Notifications impact¶
None
Other end user impact¶
User will be able to call particular deployment pieces by hand if this feature is implemented on the Nailgun side.
Performance Impact¶
Testing only small pieces at time will greatly improve the performance of the CI infrastructure. But neither the deployment speed nor the performance of the OpenStack are going to be affected.
Other deployer impact¶
Fuel Library will contain descriptions of tasks along with their metadata describing which task depends on which one thus allowing orchestration engine to create a deployment graph and traverse it putting the system into desired state.
Developer impact¶
Developer will be able to inject a deployment piece anywhere, snapshot the environment, restart deployment from the particular place if these features are supported by the orchestration or just apply any task manually on the local system without any orchestration.
Implementation¶
Implementation is going to be fairly simple. Each deployment piece is represented as a task along with its metadata, e.g. which nodes should run these tasks and in which order. Then we can rip the resources and classes created using legacy monolithic catalogue and put them into corresponding deployment manifest. After that we remove corresponding calls from legacy role and continue until there is no resources left for the legacy task.
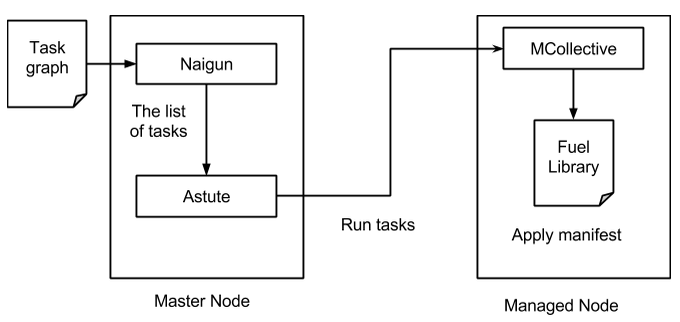
Nailgun will use the deployment graph generated from the tasks metadata. This data graph will be traversed and sent to the Astute as an ordered list of tasks to be executed with information on which nodes they should be run. Astute receives this data structure and begins to run the tasks one by one starting from pre-deploy actions, then deploy actions and, finally, the post-deploy actions. Each action reports its success and deployment is marked failed if any of them was not successful.
Granular deployment is implemented using the Nailgun plugin system that was merged some time ago and was rather successful. Nailgun uses the deployment graph data to determine what tasks on which nodes should be run. This data graph is traversed and sent to the Astute as an ordered list of tasks to be executed with information on which nodes they should be run.
Astute receives this data structure and begins to run tasks one by one. First, it doest the pre-deploy actions, then, the main deployment tasks, and, finally, the post-deploy actions. Each tasks reports back if it was successful and Astute stops deployment on any failed task.
Task graph is a yaml file that can be found at deployment/puppet/ osnailyfacter/modular/tasks.yaml in the fuel-library repository. It contains the array of tasks and their properties.
- id: netconfig
type: puppet
groups: [primary-controller, controller, cinder, compute, ceph-osd,
zabbix-server, primary-mongo, mongo]
required_for: [deploy]
requires: [hiera]
parameters:
puppet_manifest: /etc/puppet/modules/osnailyfacter/modular/netconfig.pp
puppet_modules: /etc/puppet/modules
timeout: 3600
- id Each tasks should have the unique ID that will be used to distinguish it from other tasks.
- type Determines how the tasks should be executed. Currently there are puppet and exec types.
- groups Groups are used to determine on which nodes this tasks should be started and are mostly related to the node roles.
- required_for The list of tasks that require this task to start. Can be empty.
- requires The list of task that are required by this task to start. Can be empty. Both requires and required_for fields are used to build the dependency graph and to determine the order of task execution.
- parameters The actual payload of the task. For the Puppet task they can be paths to modules and the manifest to apply and exec type requires the actual command to run. Timeout determines how long orchestrator should wait for the task to complete before the tasks will marked failed by time out.
- id: netconfig
type: puppet
groups: [primary-controller, controller, cinder, compute, ceph-osd,
zabbix-server, primary-mongo, mongo]
required_for: [deploy]
requires: [hiera]
parameters:
puppet_manifest: /etc/puppet/modules/osnailyfacter/modular/netconfig.pp
puppet_modules: /etc/puppet/modules
timeout: 3600
- id: tools
type: puppet
groups: [primary-controller, controller, cinder, compute, ceph-osd,
zabbix-server, primary-mongo, mongo]
required_for: [deploy]
requires: [hiera]
parameters:
puppet_manifest: /etc/puppet/modules/osnailyfacter/modular/tools.pp
puppet_modules: /etc/puppet/modules
timeout: 3600
- id: hosts
type: puppet
groups: [primary-controller, controller, cinder, compute, ceph-osd,
zabbix-server, primary-mongo, mongo]
required_for: [deploy]
requires: [netconfig]
parameters:
puppet_manifest: /etc/puppet/modules/osnailyfacter/modular/hosts.pp
puppet_modules: /etc/puppet/modules
timeout: 3600
- id: firewall
type: puppet
groups: [primary-controller, controller, cinder, compute, ceph-osd,
zabbix-server, primary-mongo, mongo]
required_for: [deploy]
requires: [netconfig]
parameters:
puppet_manifest: /etc/puppet/modules/osnailyfacter/modular/firewall.pp
puppet_modules: /etc/puppet/modules
timeout: 3600
- id: hiera
type: puppet
role: [primary-controller, controller, cinder, compute, ceph-osd,
zabbix-server, primary-mongo, mongo]
required_for: [deploy]
parameters:
puppet_manifest: /etc/puppet/modules/osnailyfacter/modular/hiera.pp
puppet_modules: /etc/puppet/modules
timeout: 3600
This graph data will be processed to the following graph when imported to the Nailgun. Deploy task is a anchor used to start the graph traversal and is hidden from the image.

Nailgun will run hiera task first, then netconfig or tools, and then firewall or hosts. Astute will start each tasks on those nodes which roles are present in the groups field of each tasks. If more then one task can be started by the dependencies a random task will be selected.
Previously we have used the single entry point manifest that can be found at deployment/puppet/osnailyfacter/examples/site.pp in the fuel-library repository. Granular deployment allows us to use many small manifests instead of the single one. These small manifests are placed to the deployment/puppet/osnailyfacter/modular folder and its subfolders. Writing a modular manifests is not hard at all. You should take all the resources, classes and definitions you are using to deploy your component and place them into a single file. This manifests should be able to do everything that is required for your component. Most likely the system should be in some state before you will be able to start your task. For example, database, pacemaker or keystone should be present. Achieving this state is out of the scope of your tasks and you should just believe that all the requirement are already present as you should believe that all the input variable you need can be found in Hiera. Later we’ll make pre-task tests that will check the requirements. You can also meet the missing dependencies. Some of our manifests have internal dependencies on other manifests and their parts. It’s actually a bad practice to make such dependencies, nevertheless they are present all over the Fuel Library. You will have to either remove this dependencies or make dummy classes to satisfy them.
For example, we could have a modular manifests that installs apache and creates a basic site.
# site.pp
$fuel_settings = parseyaml($astute_settings_yaml)
File {
owner => ‘root’,
group => ‘root’,
mode => ‘0644’,
}
package { ‘apache’ :
ensure => ‘installed’,
}
service { ‘apache’ :
ensure => ‘running’,
enable => ‘true’,
}
file { ‘/etc/apache.conf’ :
ensure => present,
content => template(‘apache/config.erb’),
}
$www_root = $fuel_settings[‘www_root’]
file { “${www_root}/index.html” :
ensure => present,
content => ‘hello world’,
}
While this manifests does its job it has some downsides. What it I want just install apache and neither start it nor create a basic site? What if I have another module that works with apache service and there will be a duplicate error? Let’s try to split this manifests to several tasks.
# apache_install.pp
package { ‘apache’ :
ensure => ‘installed’,
}
# apache_config.pp
File {
owner => ‘root’,
group => ‘root’,
mode => ‘0644’,
}
$www_root = hiera('www_root')
file { ‘/etc/apache.conf’ :
ensure => present,
content => template('apache/config.erb'),
}
# create_site.pp
File {
owner => ‘root’,
group => ‘root’,
mode => ‘0644’,
}
$www_root = hiera(‘www_root’)
file { "${www_root}/index.html" :
ensure => present,
content => ‘hello world’,
}
# apache_start.pp
service { ‘apache’ :
ensure => ‘running’,
enable => ‘true’,
}
We have just created several manifests. Each will do just its simple action. First we install apache package, then we create configuration file, then create a sample site, and, finally start the service. Each of this tasks now can be started separately together with any other tasks. We have also replaced $fuel_settings with hiera calls. Obviously there are some dependencies, we cannot start apache service without installing the package first, but we can start the service just after package installation without configuration and sample site creation.
The dependency graph for these tasks will look like this:
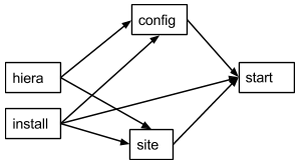
Start, config and site requires package to be installed and site and config require hiera function to work. Obviously, apache should be configured and site should be created to start. Now, let’s write a data yaml to describe this structure:
- id: hiera
type: puppet
role: [test]
required_for: [deploy]
parameters:
puppet_manifest: /etc/puppet/modules/osnailyfacter/modular/
hiera.pp
puppet_modules: /etc/puppet/modules
timeout: 3600
- id: install
type: puppet
role: [test]
required_for: [deploy]
parameters:
puppet_manifest: /etc/puppet/modules/osnailyfacter/modular/
apache_install.pp
puppet_modules: /etc/puppet/modules
timeout: 3600
- id: config
type: puppet
role: [test]
required_for: [deploy]
requires: [hiera, install]
parameters:
puppet_manifest: /etc/puppet/modules/osnailyfacter/modular/
apache_config.pp
puppet_modules: /etc/puppet/modules
timeout: 3600
- id: site
type: puppet
role: [test]
required_for: [deploy]
requires: [install, hiera]
parameters:
puppet_manifest: /etc/puppet/modules/osnailyfacter/modular/
create_site.pp
puppet_modules: /etc/puppet/modules
timeout: 3600
- id: start
type: puppet
role: [test]
required_for: [deploy]
requires: [install, config, site]
parameters:
puppet_manifest: /etc/puppet/modules/osnailyfacter/modular/
apache_start.pp
puppet_modules: /etc/puppet/modules
timeout: 3600
Nailgun can process this data file and ask Astute to deploy all the tasks in the required order. Other nodes or other deployment modes may require more tasks or tasks run in different order. What if we have got a new apache_proxy class somewhere and we want to add it to our setup.
# apache_proxy/init.pp
file { '/etc/apache.conf' :
owner => 'root',
group => 'root',
mode => '0644',
ensure => 'present',
source => 'puppet:///apache/proxy.conf',
} ->
service { 'apache' :
ensure => running,
enable => true,
}
As you can see this tasks updates main apache configuration too and it conflicts with our previous config tasks. It would not be possible to combine them in a single catalog. It also tries to enable Apache service too producing another duplicate error. Using granular deployment we can still use them together without trying to do something with duplicates or dependency problems.
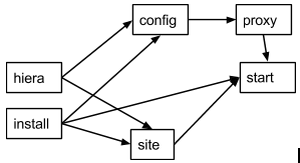
We have just inserted the new proxy task between config and start tasks. Yes, proxy task will rewrite configuration file created in config task making config task pointless, but nevertheless this setup will work as expected and we’ll have a working Apache-based proxy. Apache will be started at the proxy task but start task will not produce any errors due to Puppet’s idempotency.
Currently we have several task already merged: * hiera Together with modularization we are moving from the fuel_settings yaml to Hiera, the commonly acceptable method of passing data to the Puppet manifests. This task configures hiera backend for Puppet and uses the old astute.yaml uploaded by Astute as the first Hiera data source. After this task all the variables found in the astute yaml becomes available as for hiera function in Puppet as for the hiera CLI command. * globals During the previous years of Fuel Library development we have put a lot of data processing and mangling logic into the old site.pp file and other manifests. Now all this logic have been gathered into a single task. It should compute all global variables used throughout the Fuel Library and write them into the second data source within the Hiera data directory. After this task is completed hiera function will be able to fetch global variables and use them in other manifests.
Both hiera and global tasks are temporary workarounds used during the transition period. Later hiera should be configured during the node provisioning and all the logic inside globals task should be a part of Nailgun serializer. We should also completely rethink the hierarchy used for Hiera and implement a better method of settings distribution. Luckily, Hiera allows us to modify the structure of its data sources without any changes to the manifests that are using hiera data as long as we keep variable names same.
Globals tasks writes Hiera yaml using the template deployment/puppet/osnailyfacter/templates/globals_yaml.erb. It should contain all the global variables and can be automatically generated by the globals_template_helper.rb helper tool. If you have added or removed variables from globals.pp you should run this helper and commit the modified template.
- netconfig This is the first granular task implemented and is just configures the network interfaces on the node. It uses hiera function to fetch the input data and uses several variables that were generated by the globals task.
- firewall Configures firewall on the node.
- tools Installs several tools useful for the developers.
- hosts Updates /etc/hosts files on the node to contain records for every other nodes in the cluster.
- legacy This tasks is just a copy of the old site.pp file. It uses the old monolithic deployment method for those components we have not made a separate tasks for. This task will be removed later when we finish the modularization.
Testing this manifests becomes easier too. In this case manifests are little and they don’t require several hours to apply but we can still try to benefit from granular testing. After writing each file we can try to manually apply it to check if the task works as expected.
If the task is complex enough it can benefit from automated acceptance testing. These tests can be implemented using any tool developer sees fit. For example, let’s try to use http://serverspec.org. It’s rspec extension that is very convenient for server testing. The only thing install task does is the package installation and it has no preconditions. The spec file for it can look like this:
require 'spec_helper'
describe package('apache') do
it { should be_installed }
end
Running the spec should produce an output like this:
Package "apache"
should be installed
Finished in 0.17428 seconds
1 example, 0 failures
There are many different resource types serverspec can work with and it can easily be extended. Other tasks can be tested with specs like this:
describe service('apache') do
it { should be_enabled }
it { should be_running }
end
describe file('/etc/apache.conf') do
it { should be_file }
its(:content) { should match %r{DocumentRoot /var/www/html} }
end
This tests can later be used by our QA team to check the completion of every task during the deployment process and even during production deployment if we decide to invent a method to run them.
There is olso another popular rspec framework for acceptace testing https://github.com/puppetlabs/beaker that look similiar to serverspec but is more popular in the OpenStack community. It uses either KVM or Docker environment to test the manifests and includes means to apply tests automaticly so it’s fit for both local developer testing and centralized CI Gate testing. Unfortunately, it cannot work with local environments and cannot be used for production system testing without modifications.
Assignee(s)¶
Primary assignee: - Aleksandr Didenko aka ~adidenko - Dmitry Ilyin aka ~idv1985
Other contributors: - Almost all fuel-library contributors
Work Items¶
Trello board for the feature is here: https://trello.com/b/d0bKdE43/fuel-library-modularization
Implementation plan¶
Step #1: Split monolithic ‘site.pp’ manifest into separate tasks:
- hiera.pp
- globals.pp
- logging.pp
- netconfig.pp
- firewall.pp
- hosts.pp
- tools.pp
- legacy.pp
‘legacy.pp’ is based on our legacy site.pp manifest. So it’s mostly like previous monolithic deployment scheme where everything was deployed with a single puppet apply run.
Step #2: Move top-scope roles into separate tasks:
- controller.pp
- compute.pp
- cinder.pp
- ceph-osd.pp
- mongo.pp
- mongo_primary.pp
- zabbix.pp
Remove no longer needed manifests:
- deployment/puppet/osnailyfacter/examples/site.pp
- deployment/puppet/osnailyfacter/manifests/cluster_ha.pp
- deployment/puppet/osnailyfacter/manifests/cluster_simple.pp
- deployment/puppet/osnailyfacter/modular/legacy.pp
Step #3: Split ‘controller.pp’ task into smaller tasks:
- cluster
- virtual_ips
- cluster-haproxy
- openstack-haproxy
- openstack-controller
- swift
- heat
- sahara
- murano
- vcenter
- mellanox
Step #4: Split openstack-controller (openstack::controller class) into smaller tasks:
- openstack::db::mysql
- rabbitmq
- memcached
- openstack::keystone
- openstack::nova::controller
- openstack::auth_file
- ceph
- openstack::glance
- openstack::cinder
- openstack::horizon
- openstack::ceilometer
- osnailyfacter::apache_api_proxy
- openstack::network
Dependencies¶
Granular deployment blueprint needs to be completed at least with the first implementation that allows to execute the simplest granules. https://blueprints.launchpad.net/fuel/+spec/granular-deployment-based-on-tasks
Testing¶
Feature is considered completed as soon as there is no deployment tests failing. This feature should be mostly considered as refactoring approach, e.g. implementation rewriting, thus not affecting functionality of the deployed cloud at all.
Documentation Impact¶
Process of development will be significantly improved and this should be reflected in the development documentation.