Support VNFM for AutoHeal and AutoScale with External Monitoring Tools¶
https://blueprints.launchpad.net/tacker/+spec/support-auto-lcm
Problem description¶
Zed release supported Fault Management / Performance Management (FM/PM) interfaces, and AutoHeal and AutoScale with External Monitoring Tools [1]. However, Heal or Scale execution must be triggered by NFVO.
This spec provides some implementations for supporting receiving alerts from External Monitoring Tools and VNFM(tacker)-driven AutoHeal and AutoScale without NFVO. This implementation only supports VNF and CNF instantiated through Tacker’s v2 API.
Proposed change¶
The following changes are needed:
Add AutoHeal RESTful API to receive alerts sent from External Monitoring Tool.
POST /alert/auto_healing
Modify AutoScale RESTful API to receive alerts sent from External Monitoring Tool.
POST /alert/auto_scaling
Add fields in config file to determine if AutoHeal should be triggered or not.
Note
The External Monitoring Tool is a monitoring service. That is not included in Tacker. Operators implement the External Monitoring Tool. The External Monitoring Tool uses metrics service such as Prometheus and triggers AutoHeal and AutoScale events using the Prometheus Plugin interface.
Prometheus Plugin¶
The Prometheus Plugin is a sample implementation that operates Prometheus specific function. In this spec, there are two APIs in the Prometheus Plugin for receiving requests sent by Prometheus, and then calling Tacker’s Heal or Scale interfaces.
The Prometheus Plugin is an optional feature. The AutoHeal and AutoScale
APIs can be enabled in tacker.conf.
[prometheus_plugin]
auto_healing = True
auto_scaling = True
Triggering of AutoHeal¶
When the External Monitoring Tool detects the VNF or CNF resource failure or problem, it will send an alert message to Tacker. Tacker receives the alert and validates it. Then Tacker calls the internal Heal function for the resource. Use this Heal method to repair the failure and problem of VNF or CNF resources.
Design of Heal operation¶
The following is a schematic diagram of Heal:
+--------------------------------------------------------------------------+
| VNFM |
| +------------------------+ +----------------------------+ |
| | Tacker | | Tacker | |
| | Server | | Conductor | |
+----------------+ | | | | | |
| External | 2. POST | | 3. Check parameters and confirm vnfc_info_id | |
| Monitoring | alert | | +------------+ | | | +--------+ |
| Tool +----------------> Prometheus +-------------------------------------------> Tacker | |
| (based on | | | | Plugin | | | | | DB | |
| Prometheus) | | | +------+-----+ | | | +--------+ |
+--+-------------+ | | | 4. Heal | | | |
| 1. Collect metrics | | | | | | |
| | | +------v-----+ | | +---------------+ | |
| | | | Vnflcm +--------------> Vnflcm Driver +--+ | |
| | | | Controller | | | +---------------+ | | |
| | | +------------+ | | +---------v--+ | |
| | | | | | Infra +--------------+ |
| | | | | | Driver | | | |
| | | | | +------------+ | | |
| | +------------------------+ +----------------------------+ | |
| +----------------------------------------------------------------------|---+
| |
| +-----------------------------------------------------------------+ |
| | Kubernetes | |
| | +---------------+-----------------------------------+
| | 5. Delete failed | | 6. Create new Pod | |
| | Pod | | | |
| | +--------v----+ +------v------+ +-------------+ | |
| | | +--------+ | | +--------+ | | | | |
+----------------------------------> | Pod | | | | Pod | | | | | |
| | | +--------+ | | +--------+ | | | | |
| | | Worker | | Worker | | Master | | |
| | +-------------+ +-------------+ +-------------+ | |
| +-----------------------------------------------------------------+ |
| |
| +-----------------------------------------------------------------+ |
| | OpenStack | |
| | +---------------+-----------------------------------+
| | 5. Delete failed | | 6. Create new VM |
| | VM | | |
| | +--------v----+ +------v------+ +-------------+ |
| | | +--------+ | | +--------+ | | | |
+----------------------------------> | VM | | | | VM | | | | |
| | +--------+ | | +--------+ | | | |
| | Compute | | Compute | | Controller | |
| +-------------+ +-------------+ +-------------+ |
+-----------------------------------------------------------------+
External Monitoring Tool collects metrics and decides whether triggering alert is needed or not.
External Monitoring Tool sends POST request to
/alert/auto_healing.Prometheus Plugin receives the alert request and validates its content. Then it confirms that the
vnfc_info_idin the alert request exists in the DB.Heal operation is triggered.
The specified VM or Pod is deleted.
New VM or Pod is created.
Request parameters for operation¶
The detail of API is described at REST API impact.
Sequence for operation¶
The following describes the processing flow of the Tacker after the External Monitoring Tool sends the alert.
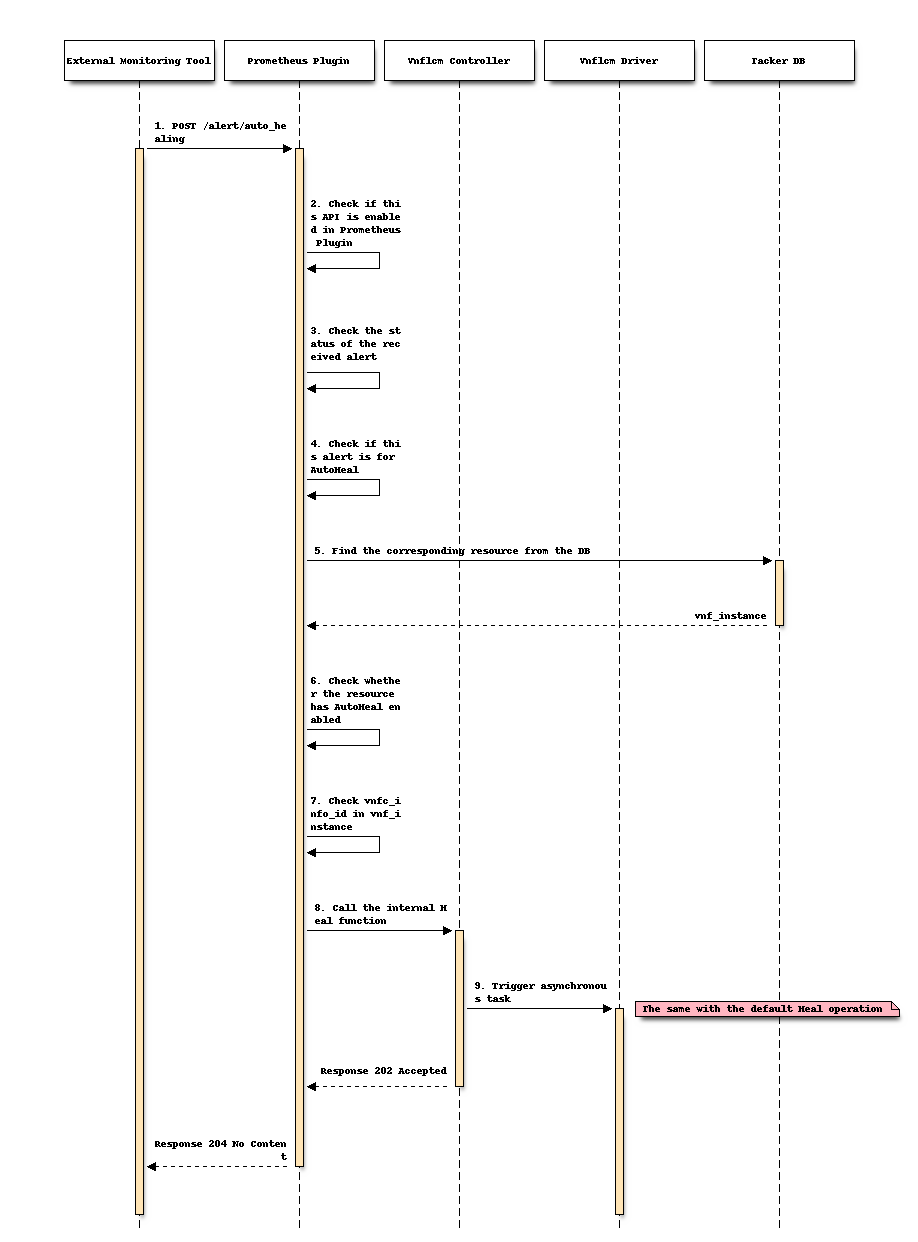
As an External Monitoring Tool, Prometheus monitors specified resources through user-defined rules. When the data monitored by Prometheus matches the conditions of the rule, Prometheus will send an alert to Tacker.
After Tacker receives the alert, Prometheus Plugin first checks that the value of the
auto_healingfield intacker.confis True. If not, the process is terminated.Prometheus Plugin checks that the value of the
statusfield in alert isfiring. If not, the process is terminated.Prometheus Plugin checks that the value of the
function_typefield in alert isauto_heal. If not, the process is terminated.According to the value of
vnf_instance_idin the label in the alert, Prometheus Plugin gets the correspondingvnf_instancefrom the DB.Prometheus Plugin checks that the key of
isAutohealEnabledexists invnf_instance.vnfConfigurablePropertiesand its value is True. If not, the process is terminated.Prometheus Plugin checks that the value of
vnfc_info_idin the alert request exists invnf_instance.vnfc_info.According to the values of
vnf_instance_idandvnfc_info_id, Prometheus Plugin calls the internal Heal function of vnflcm.From this step, it is completely the same with the default Heal operation.
Note
The default Heal operation is all = False and
specified VNFC instances are healed.
When all = True is set, specified VNFC instances and
storage resources are healed.
Note
When multiple alerts occur, the alerts should be aggregated or filtered. This implementation will prevent repeated heal operations.
Triggering of AutoScale¶
When the External Monitoring Tool detects that the CPU, memory, disk and other resources of the VNF or CNF are underloaded or overloaded, it will send an alert message to Tacker. Tacker receives the alert and validates it. Then Tacker calls the internal Scale function for the resource. Use this Scale method to balance underloaded or overloaded VNF or CNF resources.
Design of Scale operation¶
The following is a schematic diagram of Scale:
+--------------------------------------------------------------------------+
| VNFM |
| +------------------------+ +----------------------------+ |
| | Tacker | | Tacker | |
| | Server | | Conductor | |
+----------------+ | | | | | |
| External | 2. POST | | 3. Check parameters and confirm aspect_id | |
| Monitoring | alert | | +------------+ | | | +--------+ |
| Tool +----------------> Prometheus +-------------------------------------------> Tacker | |
| (based on | | | | Plugin | | | | | DB | |
| Prometheus) | | | +------+-----+ | | | +--------+ |
+--+-------------+ | | | 4. Scale | | | |
| 1. Collect metrics | | | | | | |
| | | +------v-----+ | | +---------------+ | |
| | | | Vnflcm +--------------> Vnflcm Driver +--+ | |
| | | | Controller | | | +---------------+ | | |
| | | +------------+ | | +---------v--+ | |
| | | | | | Infra +--------------+ |
| | | | | | Driver | | | |
| | | | | +------------+ | | |
| | +------------------------+ +----------------------------+ | |
| +----------------------------------------------------------------------|---+
| |
| +-----------------------------------------------------------------+ |
| | Kubernetes | |
| | +---------------+-----------------------------------+
| | | | 5. Create or Delete Pod | |
| | | | | |
| | +--------v----+ +------v------+ +-------------+ | |
| | | +--------+ | | +--------+ | | | | |
+----------------------------------> | Pod | | | | Pod | | | | | |
| | | +--------+ | | +--------+ | | | | |
| | | Worker | | Worker | | Master | | |
| | +-------------+ +-------------+ +-------------+ | |
| +-----------------------------------------------------------------+ |
| |
| +-----------------------------------------------------------------+ |
| | OpenStack | |
| | +---------------+-----------------------------------+
| | | | 5. Create or Delete VM |
| | | | |
| | +--------v----+ +------v------+ +-------------+ |
| | | +--------+ | | +--------+ | | | |
+----------------------------------> | VM | | | | VM | | | | |
| | +--------+ | | +--------+ | | | |
| | Compute | | Compute | | Controller | |
| +-------------+ +-------------+ +-------------+ |
+-----------------------------------------------------------------+
External Monitoring Tool collects metrics and decides whether triggering alert is needed or not.
External Monitoring Tool sends POST request to
/alert/auto_scaling.Prometheus Plugin receives the alert request and validates its content. Then it confirms that the
aspect_idin the alert request exists in the DB.Scale out/in operations are triggered.
There are two types of Scale processing:
If the Scale out operation is triggered, the VM or Pod in the corresponding VDU is created.
If the Scale in operation is triggered, the VM or Pod in the corresponding VDU is deleted.
Request parameters for operation¶
The detail of API is described at REST API impact.
Sequence for operation¶
The following describes the processing flow of the Tacker after the External Monitoring Tool sends the alert.
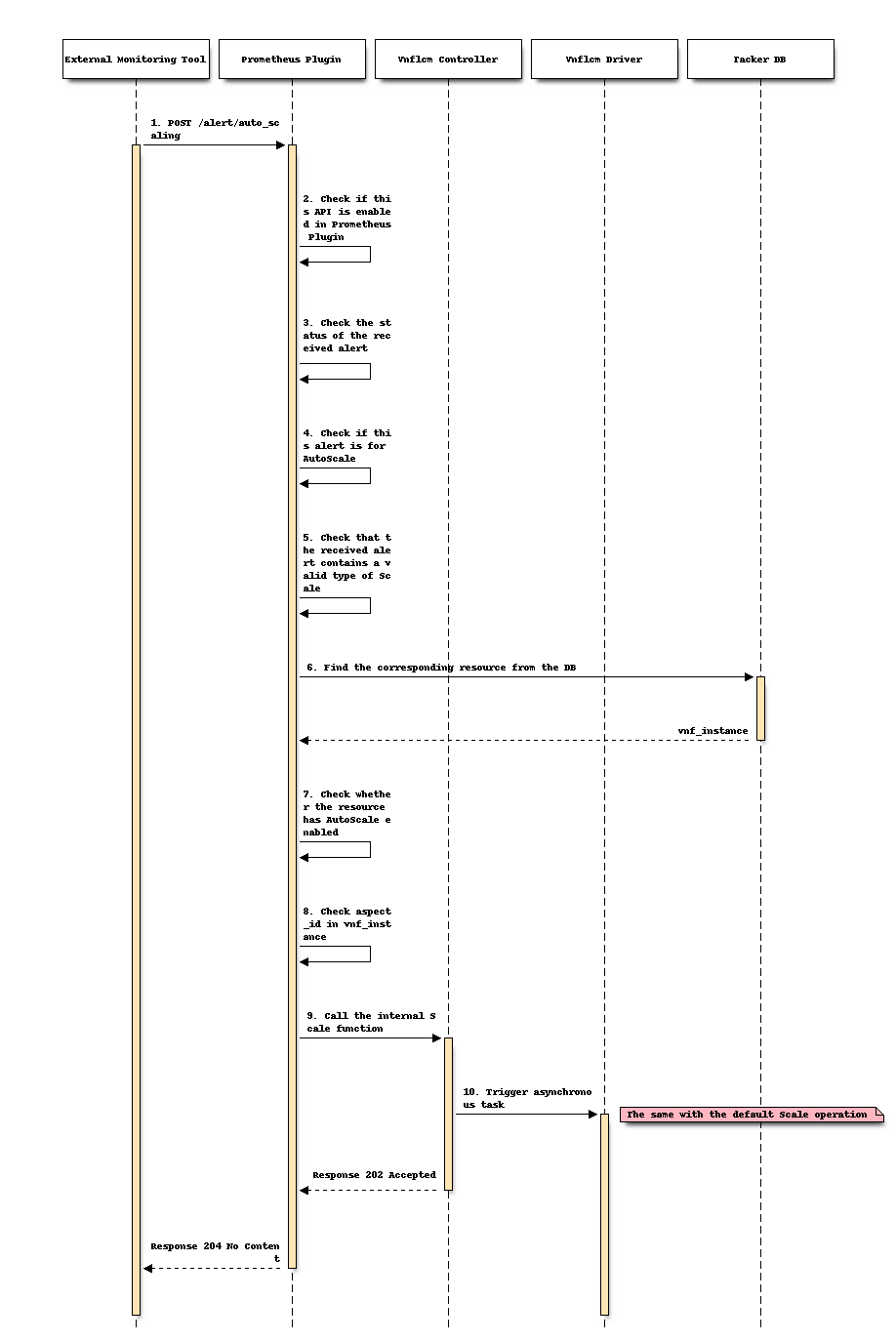
As an External Monitoring Tool, Prometheus monitors specified resources through user-defined rules. When the data monitored by Prometheus matches the conditions of the rule, Prometheus will send an alert to Tacker.
After Tacker receives the alert, Prometheus Plugin first checks that the value of the
auto_scalingfield intacker.confis True. If not, the process is terminated.Prometheus Plugin checks that the value of the
statusfield in alert isfiring. If not, the process is terminated.Prometheus Plugin checks that the value of the
function_typefield in alert isauto_scale. If not, the process is terminated.Prometheus Plugin checks that the value of the
auto_scale_typefield in alert must beSCALE_OUTorSCALE_IN. If not, the process is terminated.According to the value of
vnf_instance_idin the label in the alert, Prometheus Plugin gets the correspondingvnf_instancefrom the DB.Prometheus Plugin checks that the key of
isAutoscaleEnabledexists invnf_instance.vnfConfigurablePropertiesand its value is True. If not, the process is terminated.Prometheus Plugin checks that the value of
aspect_idin the alert request exists invnf_instance.scale_status.According to the values of
vnf_instance_id,auto_scale_typeandaspect_id, Prometheus Plugin calls the internal Scale function of vnflcm.From this step, it is completely the same with the default Scale operation.
Note
The default Scale operation is numberOfSteps = 1 and
one VNFC instance is scaled.
Alternatives¶
None
Data model impact¶
None
REST API impact¶
The following RESTful API is Tacker specific interface used for AutoHeal between Tacker and External Monitoring Tool.
- Name: Send an AutoHeal alert eventDescription: Receive the AutoHeal alert sent from External Monitoring ToolMethod type: POSTURL for the resource: /alert/auto_healingRequest:
Data type
Cardinality
Description
AutoHealAlertEvent
1
the AutoHeal alert sent from External Monitoring Tool
Attribute name (AutoHealAlertEvent)
Data type
Cardinality
Description
alerts
Structure
1..N
List of all alert objects in this group.
>status
String
1
Defines whether or not the alert is resolved or currently firing.
>labels
Structure
1
A set of labels to be attached to the alert.
>>receiver_type
String
1
Type of receiver: tacker
>>function_type
String
1
Type of function: auto_heal
>>vnfInstanceId
Identifier
1
Identifier of vnf instance.
>>vnfcInfoId
String
1
Identifier of vnfc info.
>startsAt
DateTime
1
The time the alert started firing.
>endsAt
DateTime
0..1
The end time of an alert.
>fingerprint
String
1
Fingerprint that can be used to identify the alert.
Response:Data type
Cardinality
Response Codes
Description
n/a
Success: 204
Shall be returned when a request has been read successfully.
ProblemDetails
See clause 6.4 of [2]
Error: 4xx/5xx
In addition to the response codes defined above, any common error response code as defined in clause 6.4 of ETSI GS NFV-SOL 013 [2] may be returned.
The following RESTful API is Tacker specific interface used for AutoScale between Tacker and External Monitoring Tool.
- Name: Send an AutoScale alert eventDescription: Receive the AutoScale alert sent from External Monitoring ToolMethod type: POSTURL for the resource: /alert/auto_scalingRequest:
Data type
Cardinality
Description
AutoScaleAlertEvent
1
the AutoScale alert sent from External Monitoring Tool
Attribute name (AutoScaleAlertEvent)
Data type
Cardinality
Description
alerts
Structure
1..N
List of all alert objects in this group.
>status
String
1
Defines whether or not the alert is resolved or currently firing.
>labels
Structure
1
A set of labels to be attached to the alert.
>>receiver_type
String
1
Type of receiver: tacker
>>function_type
String
1
Type of function: auto_scale
>>auto_scale_type
String
1
Type of Scale: SCALE_OUT or SCALE_IN
>>vnfInstanceId
Identifier
1
Identifier of vnf instance.
>>aspectId
String
1
The target VDU to Scale.
>startsAt
DateTime
1
The time the alert started firing.
>endsAt
DateTime
0..1
The end time of an alert.
>fingerprint
String
1
Fingerprint that can be used to identify the alert.
Response:Data type
Cardinality
Response Codes
Description
n/a
Success: 204
Shall be returned when a request has been read successfully.
ProblemDetails
See clause 6.4 of [2]
Error: 4xx/5xx
In addition to the response codes defined above, any common error response code as defined in clause 6.4 of ETSI GS NFV-SOL 013 [2] may be returned.
Security impact¶
None
Notifications impact¶
None
Other end user impact¶
None
Performance Impact¶
None
Other deployer impact¶
None
Developer impact¶
None
Implementation¶
Assignee(s)¶
- Primary assignee:
Kenta Fukaya <kenta.fukaya.xv@hco.ntt.co.jp>
Yuta Kazato <yuta.kazato.nw@hco.ntt.co.jp>
- Other contributors:
Koji Shimizu <shimizu.koji@fujitsu.com>
Yoshiyuki Katada <katada.yoshiyuk@fujitsu.com>
Ayumu Ueha <ueha.ayumu@fujitsu.com>
Work Items¶
Implement Tacker to support:
External Monitoring interface
Add new Rest API
POST /alert/auto_healingto receive the AutoHeal alert sent from External Monitoring Tool.Modify Rest API
POST /alert/auto_scalingto receive the AutoScale alert sent from External Monitoring Tool.
Add new unit and functional tests.
Dependencies¶
None
Testing¶
Unit and functional tests will be added to cover cases required in the spec.
Documentation Impact¶
Complete user guide will be added to explain how to AutoHeal and AutoScale by External Monitoring Tool.
Update API documentation on the API additions mentioned in REST API impact.
