Fuel-stats - sending of the statistics information¶
https://blueprints.launchpad.net/fuel/+spec/send-anon-usage
Fuel-stats is the service of collecting and providing analytical information about using of the Fuel product.
Problem description¶
We need to understand how customers are using Fuel. We need to collect usage statistics and provide the analytics reports.
We need to send immediate failure reports to the support team on failed deployment.
Proposed change¶
Fuel-stats service is separated into three parts. The first one is statistics collecting service (collector), the second one is analytical service (analytics), the third one is data migration tool from relational DB into analytics engine (migration).
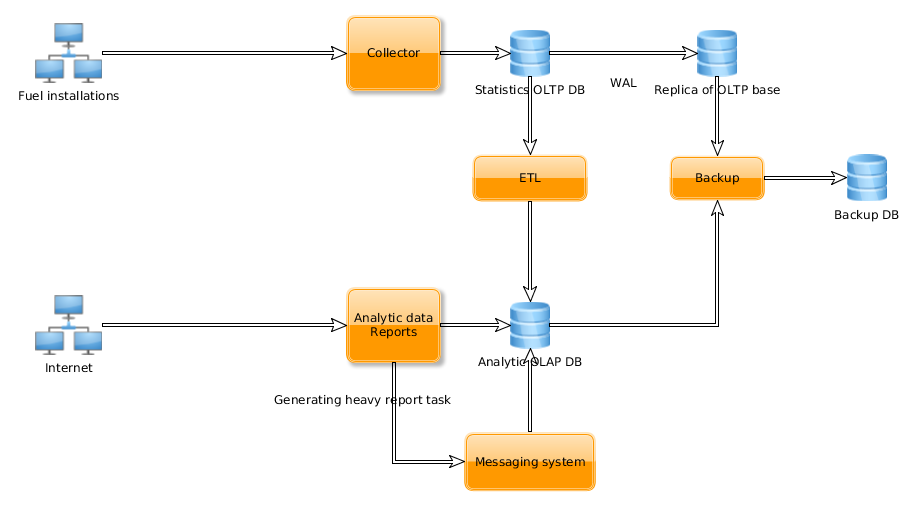
Pic 1. Fuel-stats architecture
Statistic data includes:
- Operation type (adding cluster, adding node, deployment, removing node, e.t.c.)
- Operation start and finish time (in UTC)
- Distribution / OS
- Reference architecture (e.g. HA)
- Network type (Nova-Network, Neutron with VLAN, GRE, NSX, etc.)
- Hypervisor (KVM, QEMU, vCenter, etc.)
- Storage options (Glance w/ Ceph, Glance w/ Swift, Cinder w/ LVM, Cinder w/iSCSI, Ceph, etc.)
- Related Projects (Sahara, Murano, Ceilometer, etc.)
- Number of nodes deployed
- Roles deployed to each node
- Number of environments
- Installation master node identifier (generated once during installation)
- Fuel version info (build number, release, build id, nailgun sha, fuelmain sha, ostf sha, e.t.c.)
- OpenStack version info
- Settings modified on Settings tab
- Interfaces configuration
- Disk layout
- Hardware (so we can differentiate between virtualbox and bare metal installs)
- Network verification - whether it was used, and what was the result
- Networking configuration
- Actual time (in seconds) that is took to complete the operation
- Is there any manual customizations of nodes metadata done
- Kernel parameters
- Admin network parameters
- PXE parameters
- DNS parameters
- Is fuel menu used
- Is OSTF used, and tests results
- Customer contact information, if provided
- Plugins information
On some operations we can provide only part of statistic info. All reports creation logic is implemented in the analytic. All the identifying information should be sanitized.
Statistics is grouped by the unique master node identifier which is generated once during installation or upgrade the Nailgun. Master node identifier is stored in master node settings in the Nailgun DB.
Community and commercial Fuel installations will be provided by different Fuel-stats instances. So we should provide different URIs of collector and analytics in community and commercial ISOs.
Collector service provides REST API which available from the internet. Analytics provides REST API and have UI to viewing stats reports online. Access to the analytics UI and REST API for commercial instance is limited to Mirantis network. Analytics REST API has public and private parts. Public part is available for search requests only. Private part of REST API available only on localhost. API of collector and analytics is available only through HTTPS.
Requests and responses in collector are validated by JSON Schema.
Design analytics UI is out of scope of this specification.
Each Fuel installation, with enabled sending statistics option, in random time once an hour sends info to collector API from action logs and information about cluster, nodes and other objects configurations. Each request and response to the collector API is validated by JSON scheme. After validation and processing data saves into collector DB. Collector DB has slave replica. Periodically data from collector DB extracted, transformed, loaded (ETL) into analytics DB. For performance issues ETL can be configured to work with replica DB. As analytics engine Elasticsearch is used.
Periodically backup of collector and analytics DBs is made. Collector DB’s backup is made from slave replica due to performance issues.
Analytics information can be accessed through analytics API or web UI. For heavy analytics reports can be used asynchronous processing, based on tasks and messaging system.
Option for sending statistics and customer contact information should be added into Nailgun UI. Also detailed description of sending statistics should be added into Nailgun UI.
Storing of action logs should be added into Nailgun. Each modification requested through Nailgun API should be stored into DB table action_logs. Action logs records contains actor (user, performed the operation), action name, result code, execution time, processing time, and some serialized additional info. Success and failure operations with error description are logged. Logged info should be sanitized from any credentials data. Action logs are saved always and saving is not depends on state of the ‘send statistics’ option. Nailgun tasks info also stored into the action logs table.
Requests from fuel-cli and fuel-web have custom value in the HTTP header User-Agent. ‘fuel-cli’ and ‘fuel-web’ for simple requests separation.
Execution time is calculated for asynchronous tasks, Nailgun API requests and added into action logs.
Sending of statistics from Nailgun to collecting service will be implemented as background process. This background process should save info about last sent action log and sends only fresh records. Sending process should not affect Nailgun services, should be robust to errors. It is started by supervisord. Also this process on each run sends installation detailed information: environments number, nodes number and roles, Fuel release info, OpenStack release info, network configuration, e.t.c.
Requested analytics reports:
totals/distribution for all the categories of information gathered:
- distribution of OSes of each type (CentOS/Ubuntu) by installations,
- distribution of nodes numbers by installations,
- distribution of hypervizor types by envirionments,
- average deployment time,
- how many of a given release (2014.2-6.0, 2014.2.1-6.1, etc.) are deployed,
- most common HW server type.
average number of deployment failures before success for environments,
total number of node types deployed across customers (e.g. controllers, compute, storage, MongoDB, Zabbix, etc.). This should be smart enough to recognize combined nodes as well (e.g. where compute and storage are on the same node).
number of failures for specific Health Checks vs. total runs. This would be, for example, to identify the most commonly failing test.
For sending failure reports collector API is used. On failure all required information is gathered, combined with customer contact and sent to the collector. On the collector side failure report is immediately processed and notification is sent to the support team. If customer contact is not filled only action log of failure will be stored.
Alternatives¶
None
Data model impact¶
New databases for collector and analytics will be created.
Action_logs table added into Nailgun.
In case of extra-large data amounts DB can be partitioned by DB migration scripts. If partitioning is required we can introduce it by creating master table and partitions and moving data into partitioned table. After that partitioned and original table can be swapped by renaming.
Master node settings will be added into Nailgun DB. customer contact, master node identifier are included into master node settings.
REST API impact¶
REST API for collector and analytics services will be created. API call for enabling and disabling sending statistics in the Nailgun.
Upgrade impact¶
Action logs table should be included into DB migration.
During deployment master node identifier should be generated if it not generated yet.
After upgrade information about environments, nodes, roles, networks, releases, e.t.c. will be sent into collector on scheduled action logs sending.
Security impact¶
Protection from data spoofing should be designed and implemented. Authentication should be added for access to analytics UI. Collector and analytics API available only through HTTPS.
Notifications impact¶
None
Other end user impact¶
Option for sending statistic and customer contact are added into Fuel UI settings. We must have a clear, and obvious message that we are collecting data. Information about sending statistics and customer contact form are shown at once on the popup page after authorization in the Fuel. Later they can be changed on the settings tab.
Customer contact information is added to the settings tab. This information is used in immediate failure reports for feedback and in statistics info. Contact information is:
- Last Name, First Name
- Email Address
- Company Name
By default, option for sending statistics is selected, and customer contacts are not. Statistics will be sent only if user select option ‘send statistics’ and save it in the UI.
Performance Impact¶
Performance should be measured on the large amount of action logs.
Other deployer impact¶
We require hosting for collector and analytics services and their DBs.
Collector and analytics services, DBs migrations should be deployed by puppet manifests from packages.
Community and commercial Fuel installation are provided by different Fuel-stats instances. Different URIs should be in settings of community and commercial Fuel distributions.
During deployment master node identifier should be generated if it not generated yet.
Developer impact¶
None
Implementation¶
Assignee(s)¶
Primary assignee:
- aroma@mirantis.com (Artem Roma)
- akasatkin@mirantis.com (Alexey Kasatkin)
- akislitsky@mirantis.com (Alexander Kislitksy)
Other contributors:
- jkirnosova@mirantis.com (Julia Aranovich) UI developer
- kpimenova@mirantis.com (Ekaterina Pimenova) UI developer
- acharykov@mirantis.com (Alexander Charykov) DevOps developer
- apanchenko@mirantis.com (Artem Panchenko) QA specialist
- asledzinskiy@mirantis.com (Andrey Sledzinskiy) QA specialist
- dkaiharodsev@mirantis.com (Dmitry Kaiharodsev) OSCI specialist
Work Items¶
Implementation is separated on several stages.
Used technologies¶
- Programming language - Python 2.7.
- Application server - uWSGI.
- API protocol definition - JSON Schema.
- Web service - Nginx.
- Database - PostgreSQL.
- Slave DB replica - by PostgreSQL native WAL technology.
- DB schema migrations - Alembic.
- Analytics engine - Elasticsearch
Stage 1¶
All logic should be covered by unittests.
- Configure uWSGI + Nginx + DB. Run simple WSGI application in collector
- Add JSON Schema support and validation of test request/response
- Initiate implementation of puppet manifests for service deployment, DBs backup
- Check deployment of collector and analytics, when deployment is ready
- Implement part of collector API and initiate testing and load testing of it by QA team
- Initiate implementation of enabling sending statistics and viewing statistic data
- Implement saving action logs in Nailgun
- Implement sending statistics to collector from Nailgun
- Initiate Nailgun testing by QA
- Implement logic enough for switching to implementation of analytics service
- Implement part of analytics API
- Implement data migration from PostgreSQL to Elasticsearch
- Initiate analytics UI implementation
- Implement full analytics API, collector API
- Testing, fixing
- Deploy DB, collector, analytics to servers
- Add services and servers to the monitoring of IT infrastructure
- First release is done
Limitations of the first release:
- No authentication
- No replication of collector DB
- No backup of DB
- Heavy analytics reports are not handled
- Only commercial instance is implemented (access to the analytics UI and REST API is limited to Mirantis network)
- No OSTF statistics
- No action logs viewing in the Nailgun UI
- No immediate failure reports to the support team
- No plugins statistics
Stage 2¶
- Community instance is implemented
- Improve analytics reports and analytics UI
- Action logs viewing in the Nailgun UI
- Collecting OpenStack statistics
Stage 3¶
- Handle collector DB backup
- Handle collector DB replication
- Sending OSTF and plugins statistic
- Improve analytics reports and analytics UI
- Immediate failure reports to the support team
Stage 4¶
- Handle authentication
- Handle analytics DB backup
- Improve analytics reports and analytics UI
Stage 5¶
- Handle heavy analytics reports
- Handle data partitioning (if required)
- Improve analytics reports and analytics UI
Dependencies¶
None
Documentation Impact¶
Option for enabling sending, and statistic data details should be documented.
Collector API will be documented by JSON Schemas (probably by sphinx).
Analytics reports and analytics UI should be documented.
References¶
None